Use Queries to Detect Duplicate Records
Categories:
Originally by Abshishek Ghosh and Bogdan Sturzoiu at Microsoft Development Center Copenhagen
Abstract
This pattern uses queries to create an efficient way to detect duplicate entries in a table. This is, for example, useful when trying to find out which customers or contacts have the same names, so we can merge them later.
Description
Duplicate detection has several requirements in Microsoft Dynamics NAV. One method to eliminate duplication is by defining the relevant field as the primary key. However, this method is not always practical either due to the size of the field or due to business requirements that dictate how duplicates are detected but not necessarily how they are eliminated. An example of this method is to detect contacts with the same name and take action to merge them if they are.
Before Dynamics NAV 2013, the only possibility was to iterate through the table in a loop and then create a sub-loop where another instance of the same table is filtered to check for duplicates. For example, to check for duplicate names in the Customer table, the code would look like this:
PROCEDURE HasDuplicateCustomers@26() : Boolean;
VAR
Customer@1000 : Record 18;
Customer2@1001 : Record 18;
BEGIN
IF Customer.FINDSET THEN
REPEAT
Customer2.SETRANGE(Name,Customer.Name);
IF Customer2.COUNT \> 1 THEN
EXIT(TRUE);
UNTIL Customer.NEXT = 0;
EXIT(FALSE);
END;
This code would involve setting filters on the Customer table as many times as there are records in the table. This is an expensive operation.
Starting with Dynamics NAV 2013, we can use queries to create a more efficient implementation of the same logic.
Usage
The solution involves that you create a query to return duplicates, and then invoke it from a method that would test the value of the query to identify if duplicates were found.
Step 1 – Creating the Query
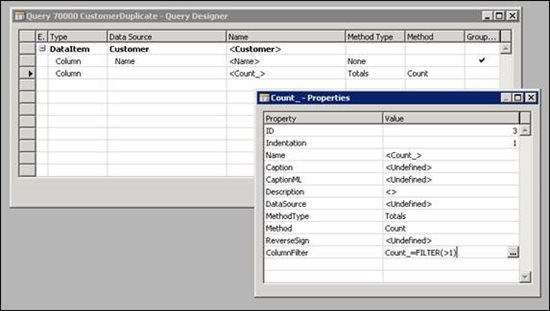
- The query must be created with the table we want to search in as the dataitem.
- The field we want to search for must be created as a grouped field.
- Create a totaling field on the count, and add a filter for Count > 1. This ensures that only records with more than one instance of the field that we selected in the previous step are included in the query result.
Continuing with our Customer Name example, here is how the query would look:
ELEMENTS
{
{ 1 ; ;DataItem; ;
DataItemTable=Table18 }
{ 2 ;1 ;Column ; ;
DataSource=Name }
{ 3 ;1 ;Column ; ;
ColumnFilter=Count_=FILTER(\>1);
MethodType=Totals;
Method=Count }
}
Step 2 – Invoking the Query to Check for Duplicates
Now that the query is created, all we need to do is to invoke the query and check if any records are returned, which would mean that there are duplicates.
Here is an alternate implementation of the HasDuplicateCustomers method using the query that we created:
PROCEDURE HasDuplicateCustomersWithQuery@27() : Boolean;
VAR
CustomerDuplicate@1000 : Query 70000;
BEGIN
CustomerDuplicate.OPEN;
EXIT(CustomerDuplicate.READ);
END;
Examples
- Acc. Sched. Chart Management codeunit (762),
methods CheckDuplicateAccScheduleLineDescription and CheckDuplicateColumnLayoutColumnHeader - Analysis Report Chart Mgt. codeunit (770),
methods CheckDuplicateAnalysisLineDescription and CheckDuplicateAnalysisColumnHeader
Consequences
A new query object is needed for every type of duplicate check. This could easily explode and create a maintenance problem.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.